deepseek-v4-pro + Harness 实战效果据网上传,目前Anthropic的所有产品均为harness模式,不过最近他们推了一个harness产品,原本把我吓了一跳,但实质一看,并不是干货,多少有点恶心人了,好东西都藏起来。我昨晚也成功验证了自己的第二个harness,工程量比是一开始做demo的100倍,平均跑完要30-50M token,10个小时左右(glm-5),并且效果还挺好。不过还是有很多优化点的,这也正是本贴的由来,在接下来…
harness 框架:还是上面那篇帖子的产物
编程模型:deepseek-v4-pro
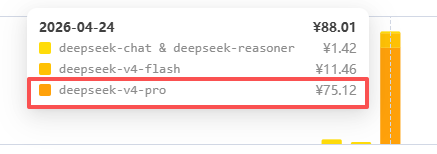
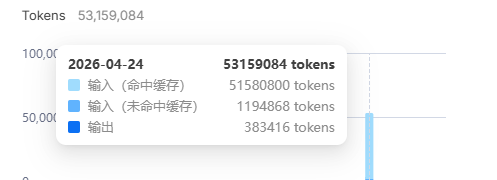
先说总结:效果拔群
如何拔群:1.之前我有发过贴说harness弥补了glm-5和sonnet 4.6的差距,那时的说法是 sonnet 4.6 是9成熟的饭,glm-5 + harness 是全熟的饭,等于是一个完全可用的系统。这里的最低要求当然也是完全可用,那优势在哪里呢,(这里就不对比代码质量了,从明显的内容出发,说实话,几千行我也懒得对比)。
可以看原帖,功能相对来说比较简陋的,而且相信大家也看得出来,页面设计比较不协调,最多最多只能算是个成品,今天这个页面体现就比前面的要好,至少至少能是个得出手的东西。
另外一点,从构建 时间上来说,之前GLM-5 + harness 构建一个 MVP版本,大概需要5-6个小时,而本次是2小时27分15秒。
我个人认为,从编码层面来说,是符合deepseek官方发布的数值的。

PS:再来看个deepseek-v4-pro讲的冷笑话

总结
Attention! Attention! Attention! 上下文飙到400k不带忘的,这种体验我只在Opus 4.5、4.6和GPT系列上体会过
attention体验排名:Opus 4.6/4.5 > GPT > DS V4 Pro(Max) >> Opus 4.7 > Gemini in Antigravity >>> 国产模型(GLM 5.1、Kimi 2.6等)
2.干活很积极,deeply seek的欲望很强,能跟GPT 5.5(xhigh)给出的plan进行两轮讨论(其他国产模型经常直接all pass,Opus差不多也能撑1~2轮)
3.速度很快,opencode部署能飙到40~50 TPS
暂时想到的主要就这三点,但我还是不建议all in DeepSeek,目前定位只能当个下位GPT替代。
吹完就该黑一下:
1.难题太慢了。虽然DS能解决其他国产模型搞不定的问题,但感觉像在手动推导,而Opus和GPT像是语料库里喂过答案,很快就定位到问题。DS的DeepSeek模式太吓人了,一个很隐蔽的bug不停推导干了我50%的周额度
2. 模型调用tools/subagents不积极,喜欢自己闷头干。这应该是post training的问题,后续应该能解决
3. 写代码还是拉胯,生产还是得靠GPT。试过一次,写完还有3、4个bugs
